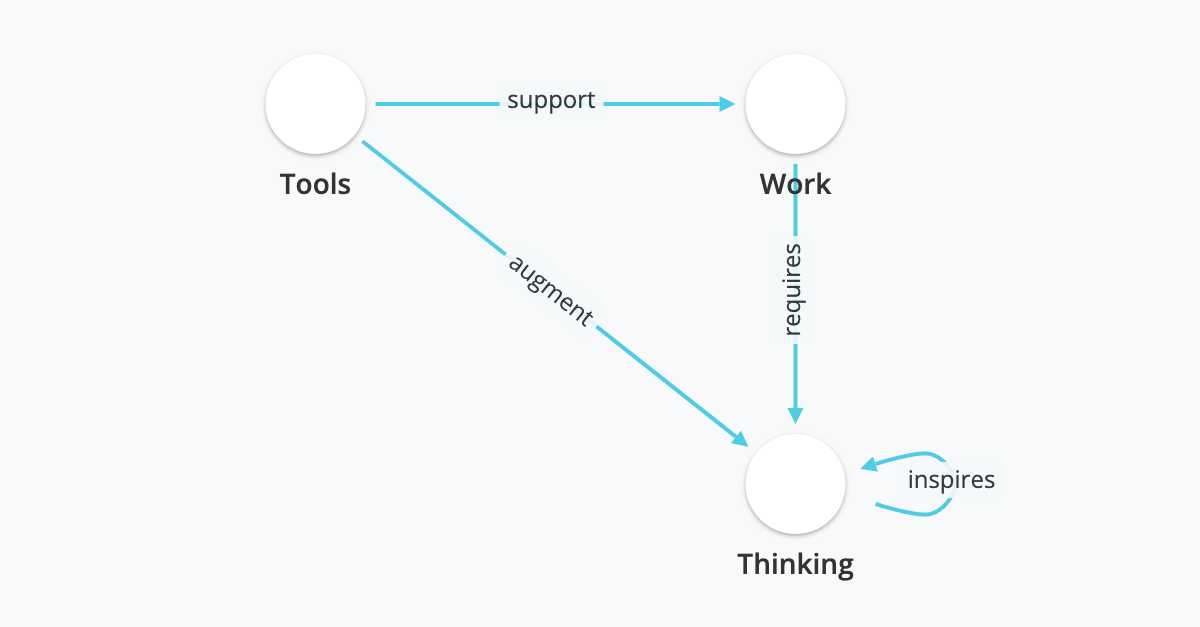
At the beginning of the year we posited that those of us who work with complex data need to move away from rows and columns and move towards graphs when thinking and working with our data. The first step is creating your model. This step is critical, and unfortunately, in my opinion, it is the least fun, mostly because this step is hard. We'd like to immediately be able to create cool network diagrams and query the data to find unique and innovative match-ups, but starting with the model is often the most non-intuitive, and over-looked step. So, while I want to jump into creating mind-blowing data visualizations, we are going to spend a bit more time with models and data entry. We want to ensure that you get the value in being able to generalize the problem you are mapping out.
Read More »