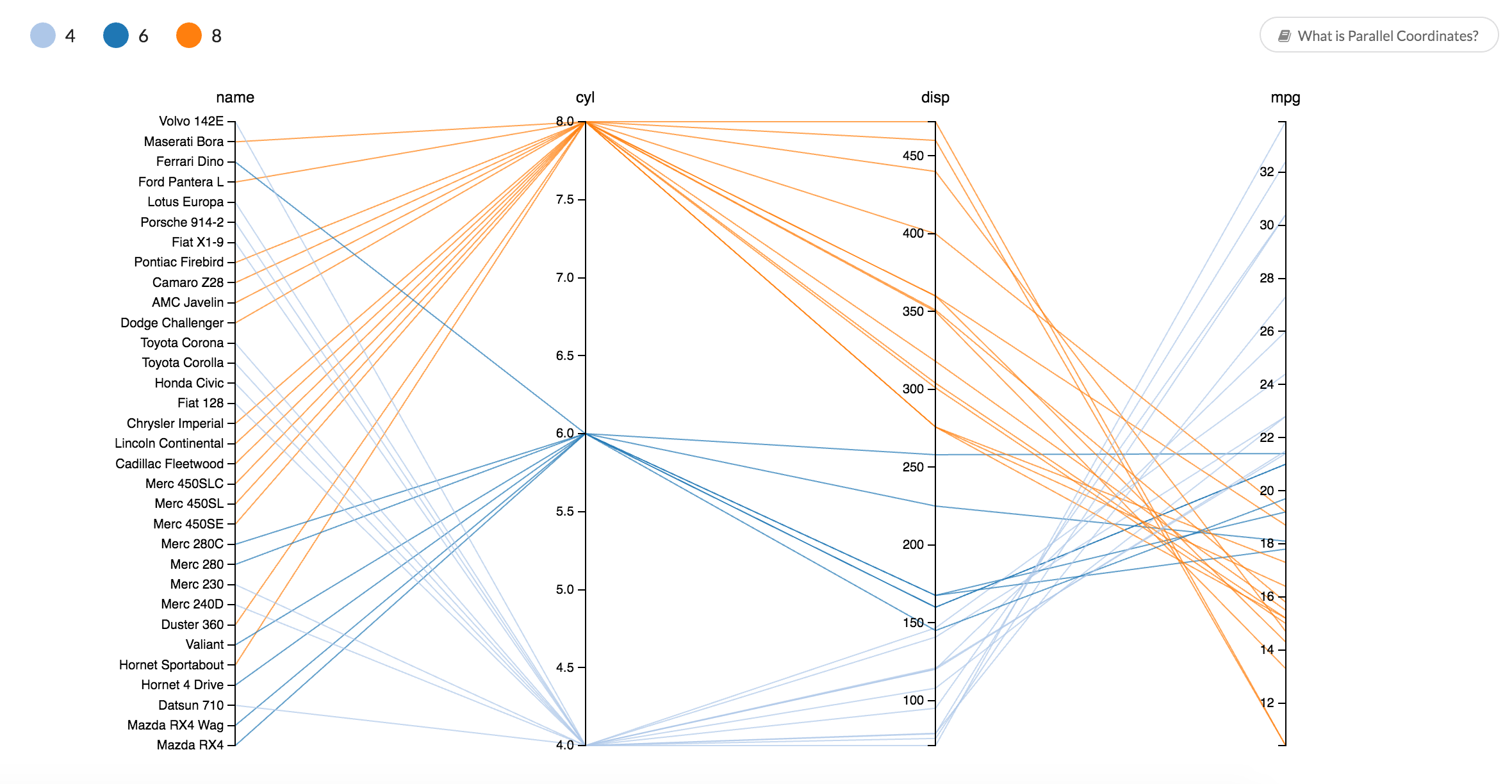
A crucial aspect that sets a data application apart from an ordinary visualization is interactivity. In an application, visualizations can interact with each other. For example, clicking on a point in a scatterplot may send corresponding data to a table. In an application, visualizations are also enhanced with simple filtering tools, e.g. selections in a list can update results shown a heat map.
Read More »